
Tokenization is useful because it significantly decreases the inference and training costs. However, tokenization has several disadvantages: vulnerability to adversarial attacks, worse performance for number and character, biases, and additional complexity.
This article explores the problems and limitations of tokenization, and delves into emerging research on tokenization-free approaches.
Motivation
Language models are trained using tokenization, which encodes text into bytes then group bytes into tokens that typically consist of subwords. Tokenization is useful because it significantly decreases the inference and training computational costs of language models. However, tokenization has several disadvantages: increased vulnerability to adversarial attacks, worse modeling performance for number and character, biases, and additional model complexity.
Why we want to remove it
The Right Unit of Computation and Concepts
The tokenization approach we have today, while effective, is arbitrary and heuristic. Humans don’t think in subwords; humans think in concepts (e.g. Beyoncé — not “Bey”, “once”, “é”). Concepts are language- and modality-agnostic and typically represent higher-level ideas. Allowing the LLM to process/manipulate concepts directly instead of subwords or bytes will make LLMs more powerful and open the door for further innovations.
Numbers, Character-level Understanding
Tokenization is one of the main reasons why LLMs perform poorly at simple spelling, character, and number manipulation tasks. This is because tokenization lacks understanding of word constituents. For example, tokenization-based LlAMA 3 scores 27% in CUTE (simple character manipulation tasks), while scoring 79% in HellaSwag (hard commonsense NLI) [ BLT paper, GPT-3 example].
Robustness and Adversarial Attacks
Tokenization suffers from sensitivity to modality, domain, and input noise. It also creates a potential attack surface. Examples:
- SolidGoldMagikarp: Where some tokens are much more common during the training of tokenizer than they are during the training of the GPT, feeding unoptimized activations into processing at test time: LessWrong blog
- Trailing Whitespaces: Prompt with space you are surprisingly creating a big domain gap, a likely source of many bugs: Scottlogic blog
- Adding noise to eval dataset like HellaSwag lead to 20% reduction in Llama 3.1 model: BLT paper
End-to-End
Tokenization means that LLMs are not actually fully end-to-end. There is a whole separate stage with its own training and inference.
Research
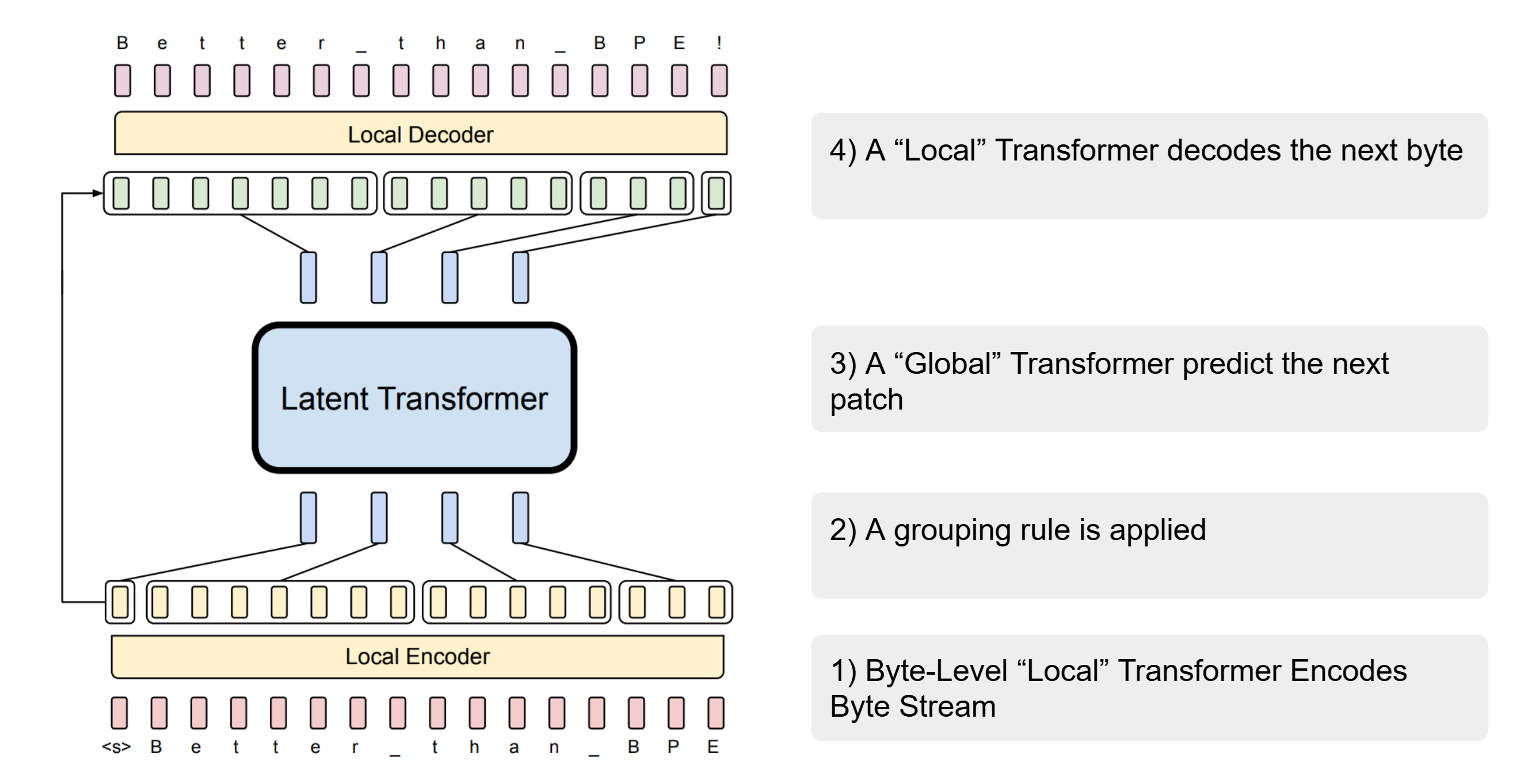
Most of the research follow the following ideas:
- A byte-level approach without grouping of bytes.
- A “local” model that encodes bytes.
- A rule to group the output of the “local” model into patches/tokens.
- A “global” Transformer.
- A “local” model that decodes patches/tokens from the “global” Transformer to bytes.
MegaByte [paper]
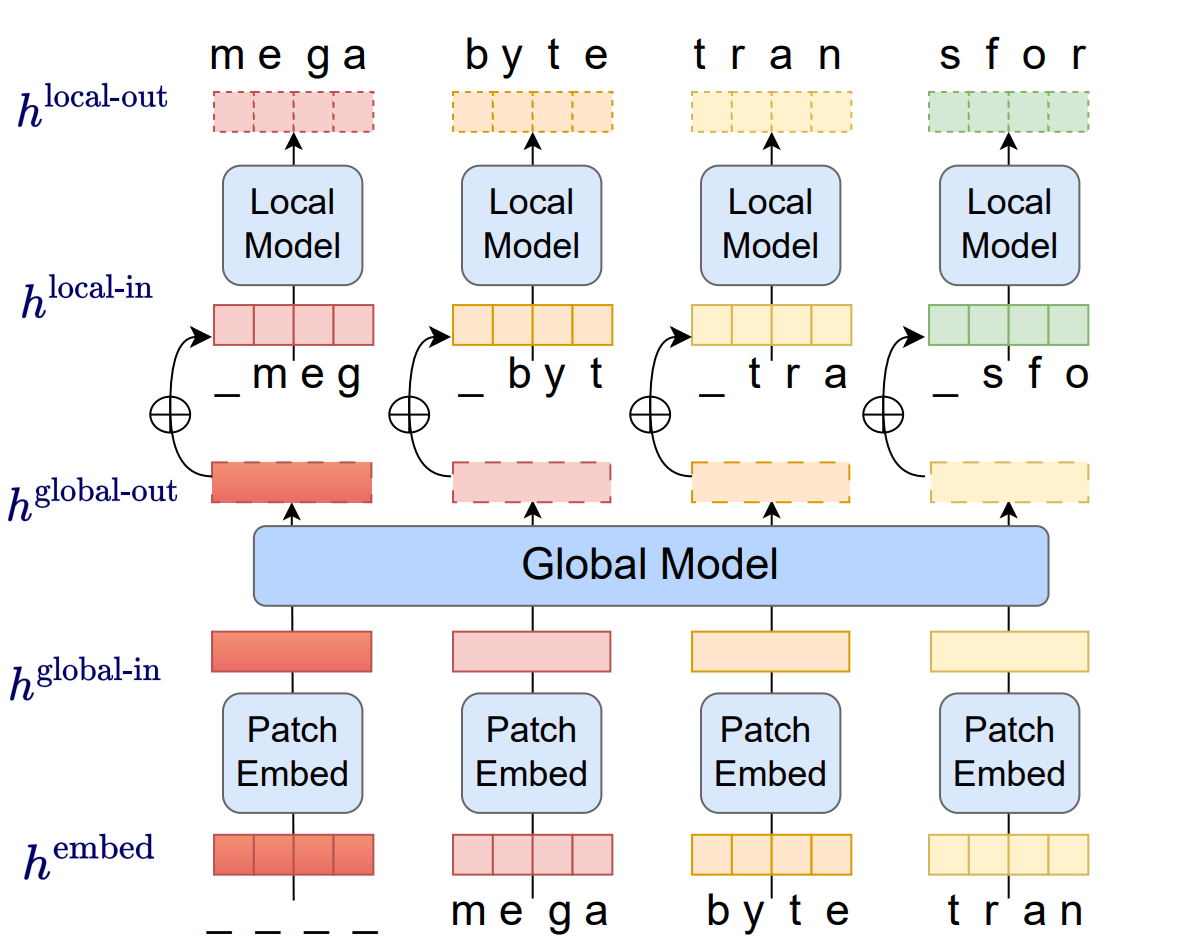 MegaByte proposes modeling bytes instead of tokens, they use multiscale Transformer, specifically, MegaByte groups bytes into patches of fixed size P (P is typically 4 or 8). Each patch of bytes is vectorized and then fed into a “global” Transformer model. The output of the global model is then fed into a “local” Transformer model that autoregressively outputs byte-level logits.
MegaByte proposes modeling bytes instead of tokens, they use multiscale Transformer, specifically, MegaByte groups bytes into patches of fixed size P (P is typically 4 or 8). Each patch of bytes is vectorized and then fed into a “global” Transformer model. The output of the global model is then fed into a “local” Transformer model that autoregressively outputs byte-level logits.
MambaByte [paper]
MambaByte improved upon this approach by replacing the local Transformer blocks with Mamba blocks to avoid the quadratic compute scaling of the attention in the local Transformer.
SpaceByte [paper]
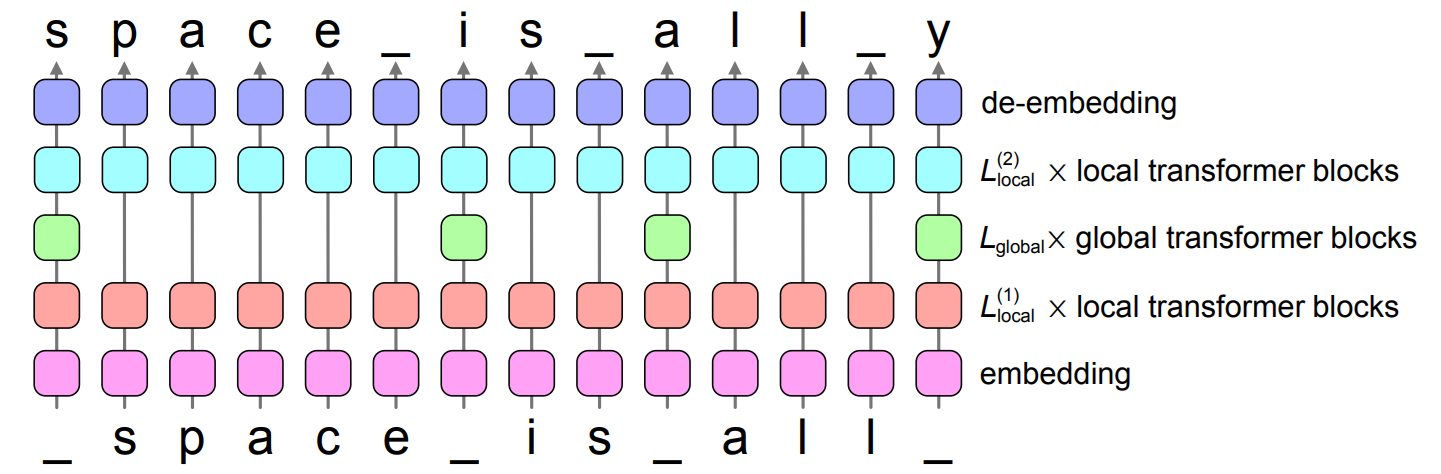 So far, the research was mostly focused on the compute aspect of LLMs and not words, concepts or the appropriate unit of compute, and the grouping is done arbitrarily. SpaceByte takes a step forward by grouping bytes based on spacelike characters rather than an arbitrarily fixed size. From the paper: “We define a byte to be spacelike if the byte does not encode a letter, number, or UTF-8 continuation byte2 . We apply the global blocks after any spacelike byte that is not preceded by another spacelike byte (and after any BOS token)”.
So far, the research was mostly focused on the compute aspect of LLMs and not words, concepts or the appropriate unit of compute, and the grouping is done arbitrarily. SpaceByte takes a step forward by grouping bytes based on spacelike characters rather than an arbitrarily fixed size. From the paper: “We define a byte to be spacelike if the byte does not encode a letter, number, or UTF-8 continuation byte2 . We apply the global blocks after any spacelike byte that is not preceded by another spacelike byte (and after any BOS token)”.
Basically the “Global” Transformer is applied to the first letter of words. This is more into the right direction, it leverages the natural pattern of human language. SpaceByte was the first tokenization-less LLM that can match the performance of tokenization-based LLM.
Byte Latent Transformer / BLT [paper]
Space based segmentation is a great first step, but not all the words represent concepts or require the same amount of computation. Byte Latent Transformer / BLT uses entropy-based grouping to dynamically segment bytes into patches. Patches are created based on the entropy of the next byte, allocating more compute and model capacity to complex regions.
 From the paper:
From the paper:
BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it.
Why Entropy based grouping?
Rather than relying on a rule-based heuristic such as whitespace, BLT instead takes a data-driven approach to identify high uncertainty next-byte predictions. BLT introduces entropy patching, which uses entropy estimates to derive patch boundaries. They trained a small byte-level auto-regressive language model on the training data for BLT and compute next byte entropies under the LM distribution pe over the byte vocabulary V:
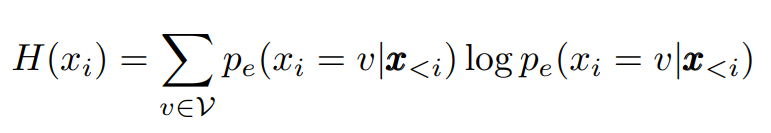 They experimented with two methods to identify patch boundaries given entropies H(xi). The first, finds points above a global entropy threshold. The second, identifies points that are high relative to the previous entropy. The second approach can also be interpreted as identifying points that break approximate monotonically decreasing entropy within the patch.
They experimented with two methods to identify patch boundaries given entropies H(xi). The first, finds points above a global entropy threshold. The second, identifies points that are high relative to the previous entropy. The second approach can also be interpreted as identifying points that break approximate monotonically decreasing entropy within the patch.
BLT models showed very promising results outperforming tokenization based LLM in CUTE (simple character manipulation tasks), noisy datasets and equally important BLT models show that it scales better than tokenization-based models.
Large Concept Model / LCM [paper]
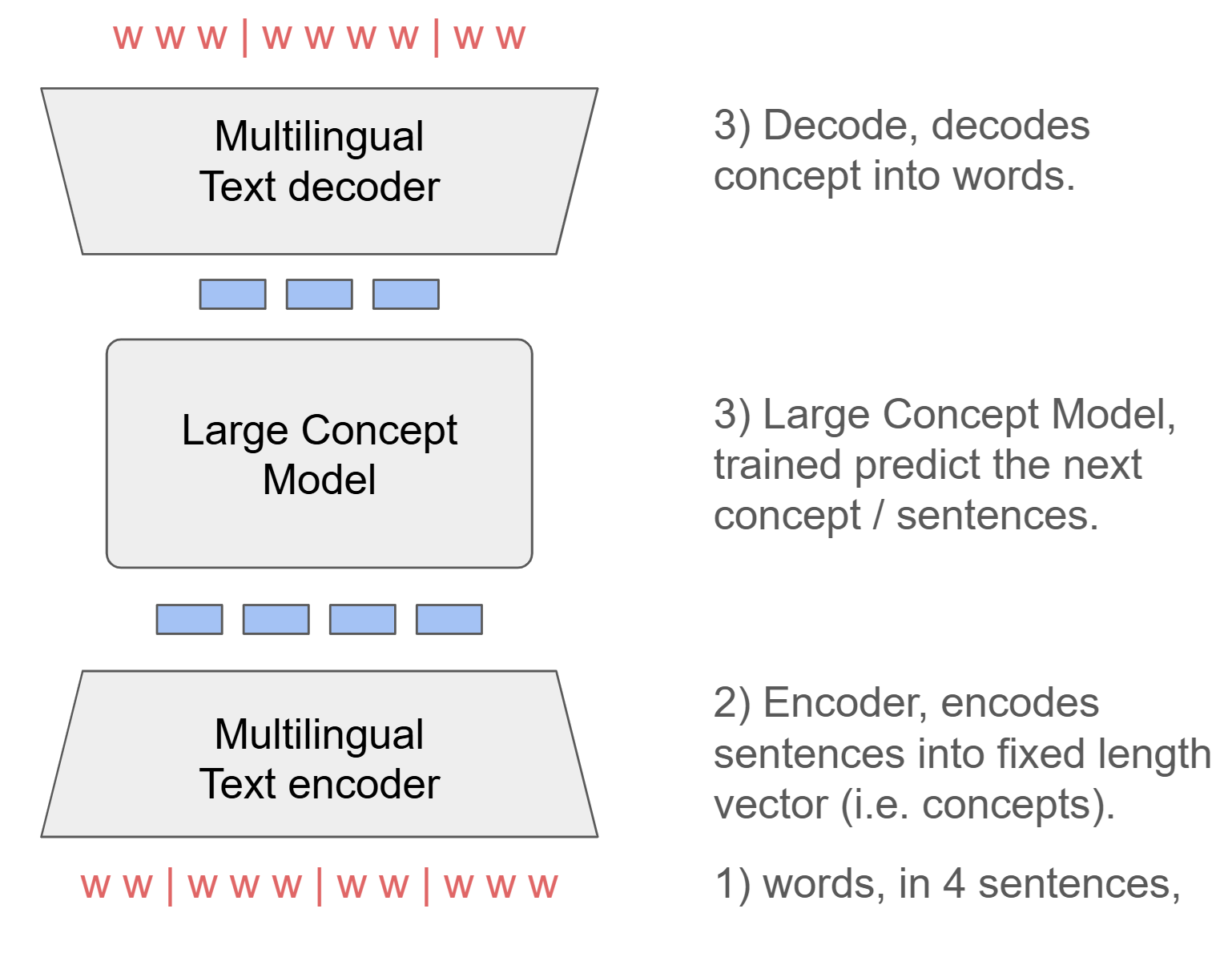 Another idea is to forgo the token level of the typical LLM and instead operate on the sentence or concept level directly. LCM / Large Concept Model include a sentence encoder that encodes sentences into an embedding space (a high dimensional, fixed size embedding), then the language/concept model predict the next sentence embedding, then a decoder that decode embedding predicted by the language/concept model into words.
Another idea is to forgo the token level of the typical LLM and instead operate on the sentence or concept level directly. LCM / Large Concept Model include a sentence encoder that encodes sentences into an embedding space (a high dimensional, fixed size embedding), then the language/concept model predict the next sentence embedding, then a decoder that decode embedding predicted by the language/concept model into words.
This is another good research direction worth pursuing, it has several advantages:
- Enables modeling of thoughts or higher level of abstraction directly.
- Efficient at handling of long contexts, and efficient during inference.
- Better at generalization and multimodality.
That being said, this approach still have open research questions, such as:
- Granularity: Sentences vary in their complexity and how much knowledge they contain. From the paper: “The choice of granularity for LCM is hard, as long sentences (>120 characters) could reasonably be considered as several concepts”.
- Specificity: The language/concept model inability to observe specific information (e.g. specific numbers, tokens, characters) could limit its reasoning ability.
Future: Promise and Open questions
We’re approaching the possibility of removing tokenization entirely. Predictions:
- By 2026: ~25% of models may abandon tokenization.
- By 2028: ~75% of models may abandon tokenization.
- Grouping Strategies: entropy + monotonicity seems like a good first step, it’s also more granular than sentence embedding. But what next?! And how can we better align with concepts?
- Scaling: Will tokenization-less models performance scale as effectively as tokenization-based ones?
- Multimodal Impact: How will tokenization-less models handle other modalities, such as images and videos?