
Recent discussions suggest that Scaling Laws in AI might be slowing. But does this mean innovation is hitting a ceiling?
This article explores the scaling law, laws governing advancement in technology, and human nature…
Part 1 - Is it really slowing and if so why…
Advancement in math, reasoning, language, and the Chat Arena benchmark have indeed been slightly slower in 2024 compared to the rapid progress of 2023 and 2022. However, while these areas have slowed slightly, we’ve witnessed the release of multimodal models like GPT-4o and LLAMA 3.2.
The bottom line is, this slowdown is natural. As benchmarks are saturated — when high accuracy or near-complete solutions are achieved — engineers naturally shift focus to new frontiers, such as vision, audio, and multi-step reasoning, instead of solely refining existing capabilities.
Human nature and the scaling laws…
Some argue that scaling laws are slowing or even breaking. This is not true—at least, not yet.
Interestingly, this narrative echoes similar "doom and gloom" predictions in other fields. Take Moore’s Law, which predicts that the number of transistors on integrated circuits doubles roughly every two years.
Critics have predicted its demise for over 20 years, yet Moore's Law remains alive, supported by robust roadmaps from industry leaders like IMEC, TSMC, and Intel [ref]. As Peter Lee, Microsoft Research VP, once joked: "The number of people predicting the death of Moore’s Law doubles every two years".
This phenomenon isn’t unique to technology. The U.S. Bureau of Mines in 1919 and M. King Hubbert in 1956 predicted that we will run out of Oil soon. Thomas Malthus in 1798 and Paul Ehrlich in 1968 predicted that we will run out of food "The battle to feed all of humanity is over. In the 1970s hundreds of millions of people will starve to death in spite of any crash programs embarked upon now".
What all those predictions missed is human ingenuity, our ability to think creatively, to innovate and find solutions.
So, what the scaling law tells us…
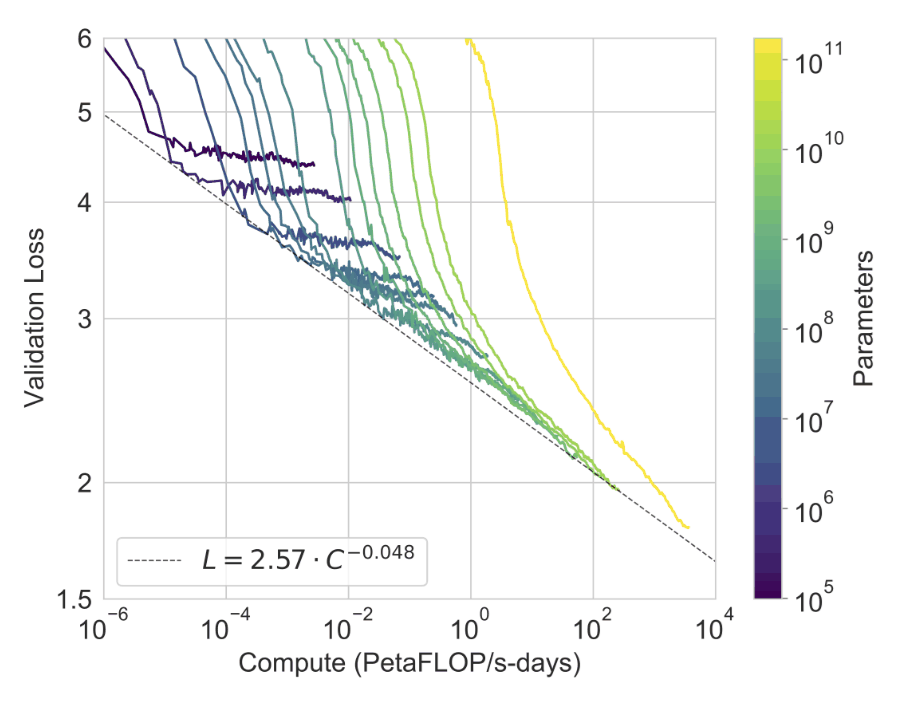
The scaling law [ref] predicts a ~20% reduction in loss for every order-of-magnitude increase in compute (i.e. increase in compute here means a combination of model size, amount of training data, training time/compute). It’s important to remember, the scaling law doesn’t guarantee uniform improvements across all downstream tasks.
To put that in perspective, if we make the simplistic assumption it translates directly for a given benchmark with 80% accuracy, with the order of magnitude increase of compute the new accuracy will be 84%.
Scaling also faces practical challenges, Software moves much faster than Hardware. While Nvidia's latest GPUs (Blackwell) offer 3x-6x performance improvements over their predecessors (Hopper), training larger models is hard and constrained by hardware, power, and economics. This has spurred innovation in areas like parallelism (to maximize the cluster utilization and efficiency), reward optimization (RLHF, DPO), synthetic training data (to maximize training signal and compute), and inference-time techniques like (Chain of Thought - CoT, Tree of Thought - ToT, and Reflection),
Part 2 - The Pattern of Technological Progress
Advancement in technology doesn’t follow a linear trajectory. It follows two laws: the law of diminishing return and law of accelerated return.
The law of diminishing return predicts that progress is characterized by an S-curve with a long gestation period, followed by rapid accelerating progress, then finally an extended period of incremental progress along a diminishing return curve.
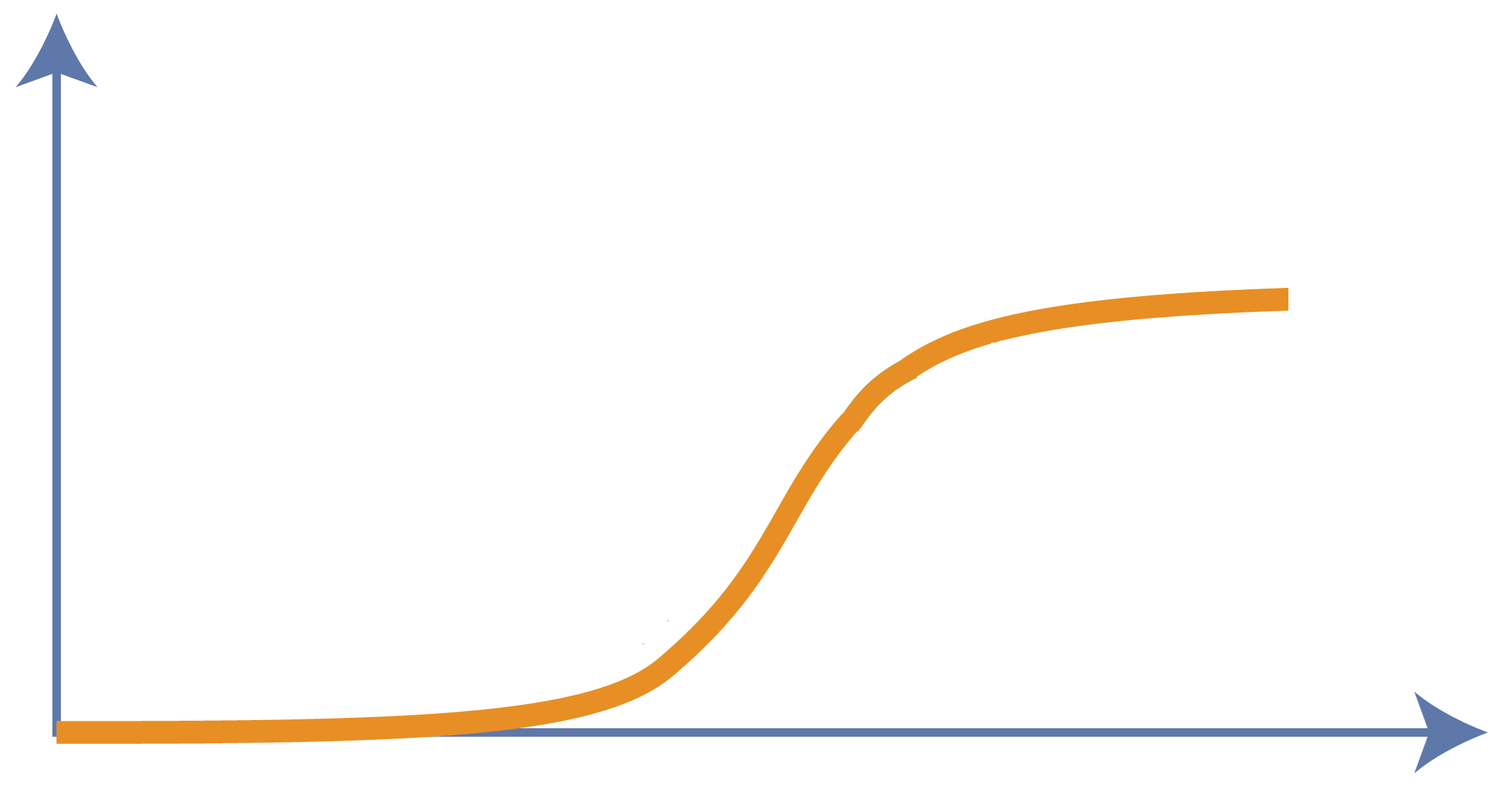
When one S-curve plateaus, a new breakthrough comes along, starting another S-curve, stacking upon the previous one. The stacked S-curves gives us the law of accelerated return [Kurzweil’s Law (aka “the law of accelerating returns”)].
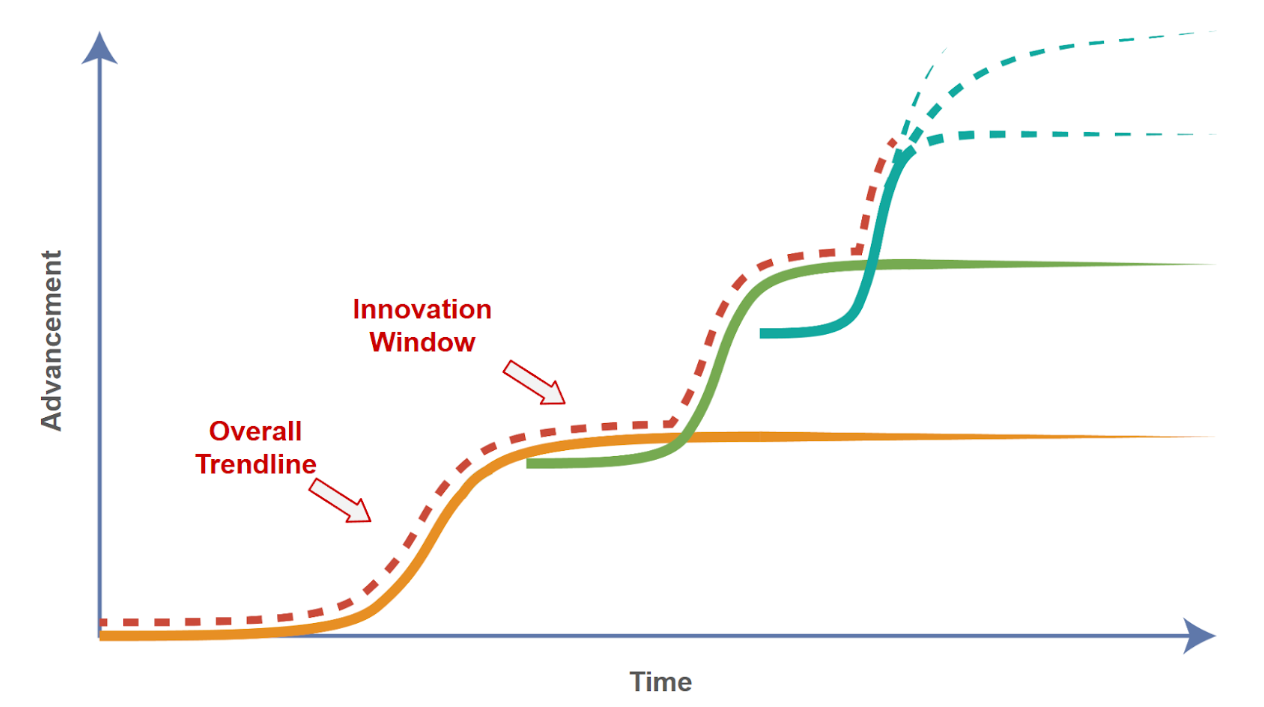
Stacked S-curves can be seen throughout history:
Machine Learning:
- 1980s K-Nearest Neighbors, Rule-based, Backpropagation algorithm
- 1990s Decision Tree, Boostomg, SVM
- 2000s Kernel SVM, LSTM, Random Forest
- 2010s Neural Network & CNN, AE/VAE, Pre-training and Deep Learning
- 2020s Web scale Deep Learning, Transformers, Diffusion
- 1920s Rotary phones
- 1960s Dial Pad Phones
- 1970s Cordless phones
- 1980s Cell phones
- 1990s Texting
- 2000s Smartphones: Internet, Apps, Cameras, etc.
- 2010s Better Smartphones: Faster connectivity, Video Camera, More sensors.
Part 3 - What’s Next for Language Models
Iterative Improvements: More economical training, inference, improve models, specially smaller models
Beside the push for bigger GPU clusters to train the next generation of LLM. There is an equally significant push to improve the economics and efficiency of LM training and inference. Smaller models (SLM) have gotten significantly better in recent months thanks to leveraging syntactic data, careful prompt curation, improving RL reward function/model (e.g. Reinforcement Learning with Verifiable Rewards (RLVR)), Direct Preference Optimization on both off- and on-policy preference data, tweaking the optimizer and the model architecture. This trend will continue, as smaller more efficient models are easier to deploy at scale. Beside more economical models, training and inference, there is increasing research around improving the model via spending more time during inference (e.g. Chain of Thought - CoT, Tree of Thought - ToT, and Reflection).
More Applications (e.g. agents)
Workflow automation (i.e. UI Automation) is the next frontier, especially with multimodal systems integrating vision and audio. Recently several benchmarks, datasets, testing arenas, and a few models have spawned preparing the field for more rapid progress in the near future.
Agents will allow us to automate computer tasks by taking over the computer to execute a sequence of tasks for us. While this is still in its infancy it has a big potential, like the movie Her, you will be able to speak to an agent and tell it what to do on your behalf on your computer. Earlier agents research focused on API/Function calls, merging both UI automation and API calls will make future agents very powerful and useful, but also open a new attack vector.
Searching for the next big thing
Scaling: Current SoTA models (e.g. GPT-4o, LLAMA 3.1) trained using approximately 25,000 Nvidia A100 GPUs. There are efforts at serval companies to build larger clusters (e.g. 100,000+ Nvidia H100/B100 GPUs - which 16x to 50x the FLOPs of the current generation clusters) those big clusters will be challenging to build, power, cool, maintain, and use, but it will allow us to build approximately an order of mangauge larger model.
Planning: LLMs can plan but its planning capabilities are still limited, specially when it comes to hierarchical planning, which is a crucial element for understanding and interacting with the world at multiple levels of abstraction.
Robotics: How could we use LLMs in robotics - I don’t mean using LLM in a specific sub-task of robotics - but in an end-to-end way, give a robot a verbal command (e.g. go wash the dashes, or, fetch the blue pants from my room), then robot decompose it into a set of motor commands. This is an open area of research and very related to hierarchical planning and long term memory.
Hallucination: Generating false Information in a convincing sentence or nonsensical response is a hard problem to solve, it’s hard because of how LLM stores knowledge, how training/feedback/reflection work in LLMs, and because we don’t want to just reduce it by 5%, we want to eliminate it. Also human expectation plays a role, we humans hallucinate but we set a very high bar for LLMs.
More data and more modality:
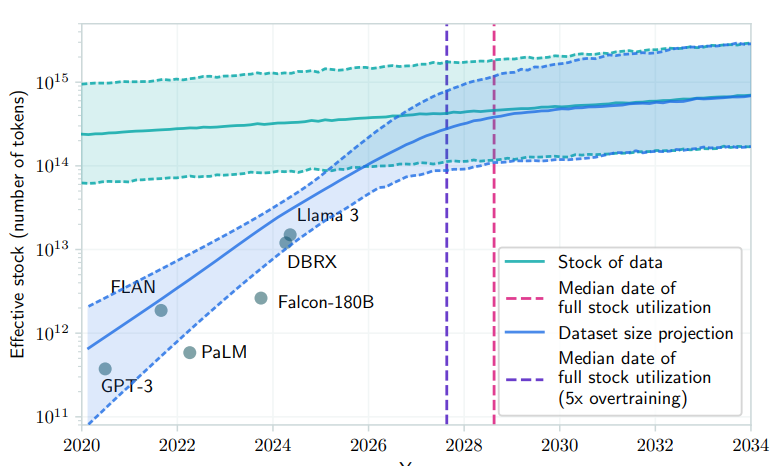
The amount of training data is not the only way to scale / improve LLMs. But there are some papers [ref] suggesting that we’re consuming a significant portion of the data available online today.
While I’m skeptic (given that we’re generating a significant amount of data every year), we also need to look beyond the Web data and books and text tokens as the main modality. Integrating additional modality natively into LLMs is a necessary step toward AGI - it helps anchor their understanding in reality, and improve generalization.
Here are some ideas: Video & Audio: Movies, Video & Audio: Personal Videos (e.g. Youtube), Audio: Music
Conclusion
While scaling laws may appear to slow, the broader trajectory of AI development continues its march forward with new capabilities (e.g. multimodality - vision, audio, multi-step reasoning).
History shows that innovation thrives on challenges, and new breakthroughs will pave the way for the next era of technological progress — the next S-curve. The question isn’t whether we’ll overcome these hurdles—but how.