TL;DR
- We present a new State-of-The-Art LLM model that reduce the gap to GPT-4.
- We achieve this by leveraging and focusing on high-quality data, diversity of the datasets and objectives, and factual finetuning with DPO.
1. Introduction
This project (still in-progress but with impressive results so far) aims to explore the limits of existing LLM performance and enhance existing LLM but not by focusing on the scale (i.e. model size, computation, number of tokens used in training), instead by focusing on data quality and training objectives. The key insights / hypothesis for this work are twofold:
- The quality of the training data plays a critical role in model performance. While this has been known for decades, almost all LLM today (both open source and proprietary) focus on the size. Earlier research like “Textbooks Are All You Need" provided some insight and motivation for this work.
- Diversity of the objectives have shown to improve generalization. We think that increasing the diversity of the tasks with focus on quality, more than the size of the training dataset would result in better generalization. Earlier research like “Robustly Optimized and Distilled Training for Natural Language Understanding” provided some insight and motivation for this work.
The starting point (i.e. baseline) is going to be the Mixtral 8x7B model. In section 2, we will recap the basics of the model. In section 3 we will describe our pre-training approach, section 4 will cover our fine-tuning approach that focuses on factuality, section 5 will cover our multi-task fine-tuning approach and our final model, finally section 6 will cover the results.
2. Recap the basics of Mistral and similar modern LLMs
To start I will explain the difference between modern LLM (e.g. Mistral and Llama) and the original Transformer models.
Training Differences
Mistral didn't release much information about how the model was trained. So we will just skip this part. My best guess is Mistral followed Llama recipe but with tuning such as: better pre-processing of the data, better data filtration for diversification, deduplication, bias, and quality, and more recent dataset, etc.
Architecture Differences
Most recent LLM such as Mistral, Llama follow what we call Transformer++ which a a pre–norm transformer + RMS normalization, SwiGLU activation in inverted bottleneck FFN, and rotary embedding. Here are summary of those changes:
Rotary Embedding
Before Rotary Embedding improves upon and unify absolute and relative embedding. Rotary Embedding (i.e. RoPE) encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation.
The mechanism is simple, we like a positional encoding function for an item and its position such that, for two items and at position and , the inner product between and is sensitive only to the values of , , and their relative position. Rotary embedding achieve this by taking into account that the dot product between two vectors is a function of the magnitude of individual vectors and the angle between them. With this in mind, the intuition behind RoPE is that we can represent the token embeddings as complex numbers and their positions as pure rotations that we apply to them.
For more details, this article provide in depth overview of Rotary Embedding
Here is Llama code for applying rotary embedding
SwiGLU Activation function in FFN
Both LLaMA and Mistral uses SwiGLU,
SwiGLU was introduced in 2020 paper GLU Variants Improve Transformer [https://arxiv.org/pdf/2002.05202.pdf] and it's known to consistently outperforms ReLU, GLU, and GELU, equally important the Swish family of functions (e.g. Swish, SwiGLU) are more stable and smoother, which lead to faster conversion, and potentially better generalization.
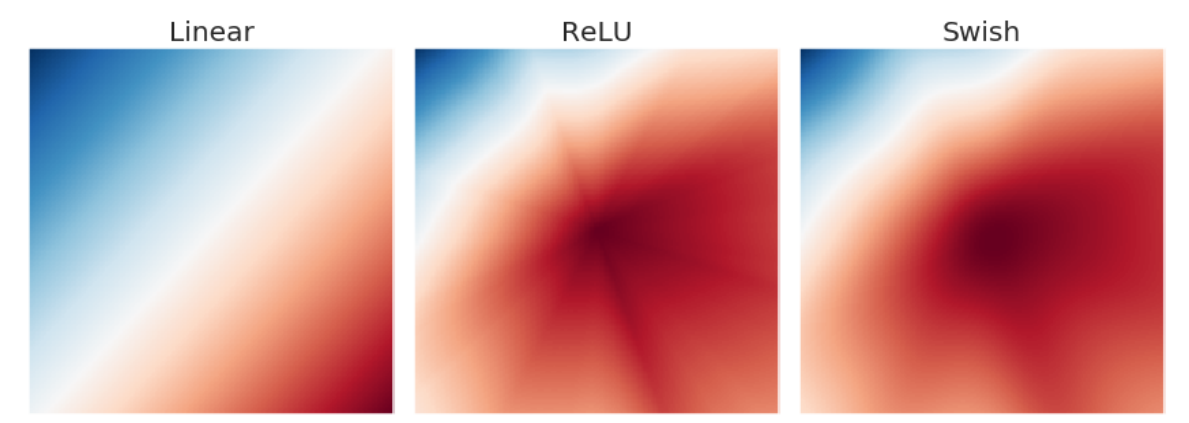 The output landscape of a random neural network with different activation functions. Specifically, we randomly initialize a 6-layered neural network, pass in as input the x and y coordinates of each point in a grid, and plot the scalar network output for each grid point. from the paper.
The output landscape of a random neural network with different activation functions. Specifically, we randomly initialize a 6-layered neural network, pass in as input the x and y coordinates of each point in a grid, and plot the scalar network output for each grid point. from the paper.
FFN with Inverted bottleneck
Both Mistral and LLAMA have FFN blocks with 3 weight matrices, as opposed to two for the original Transformer. That's because the SwiGLU contains 3 matrices (W1, W2, W3). This doesn't change the computation or the total number of parameters meaningfully, as the number of hidden units dff (the second dimension of W1 and W2 and the first dimension of W3) by a factor of ⅔ when comparing these layers to the original two-matrix version.
RMSNorm
Instead of Layer normalization, RMS Normalization is a simple modification that gets rid of the re-centering invariance in LayerNorm.
LayerNorm:
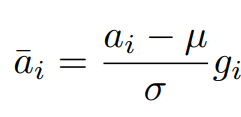
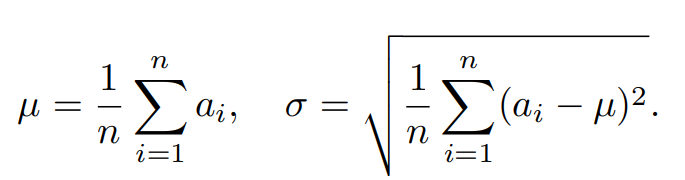
RMSNorm:
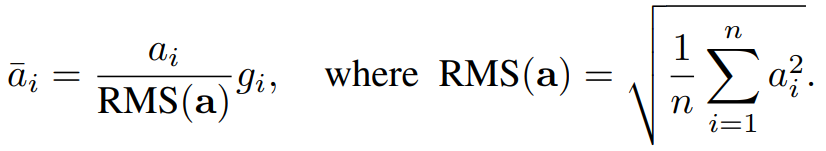
Grouped-Query Attention
Multi-head attention (MHA) while achieved impressive results, it's very expensive computationally, specially for long context which is typical for modern LLM. multi-query attention (MQA) is a mechanism that uses only a single key-value head for multiple queries, which can save memory and greatly speed up decoder inference. However, MQA can lead to quality degradation. Grouped Query Attention (GQA) [https://arxiv.org/pdf/2305.13245.pdf] is a method that sit between multi-query attention (MQA) and multi-head attention (MHA). It aims to achieve the quality of MHA while maintaining the speed of MQA.
Grouped-query attention divides query heads into G groups, each of which shares a single key head and value head. GQA-G refers to grouped-query with G groups. GQA-1, with a single group and therefore single key and value head, is equivalent to MQA, while GQA-H, with groups equal to number of heads, is equivalent to MHA.
 Here is a simple implementation by the GQA author. Here is the Llama implementation for GQA.
Here is a simple implementation by the GQA author. Here is the Llama implementation for GQA.
Sliding Window Attention (SWA)
Llama doesn't employ SAW, only Mistral. The sliding window attention reduces computation and memory need for LLM by making each layer attend to the previous N tokens (e.g. 4,096), instead of all the previous tokens. Given the stacked nature of the Transformer attention architecture, the sliding window still can attend to the tokens that are far beyond the N (e.g. 4,096). A token at layer attends to tokens at layer . These tokens attended to tokens . Higher layers have access to information further in the past than what the attention patterns seem to entail. Here is the Mistral implementation for SWA.
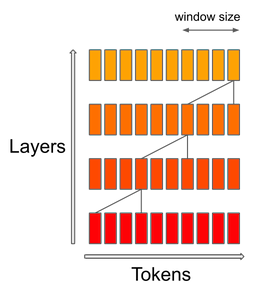 From https://mistral.ai/news/announcing-mistral-7b/
From https://mistral.ai/news/announcing-mistral-7b/
Mixture of expert
Only Mixtral 8x7B applies Mixture of experts. One way to think about the FFN and the Attention blocks within each of the transformer layers is that, the attention tries to understand what the token means given all other tokens (based on the idea that the meaning of a word depend on the other words in the sentence/context) and collect information about the neighbors or interact with the neighbors, the FFN on the other hands tries to think or process that information. Mixture of expert (i.e. MoE) allows us to have multiple experts based on the token or some gating mechanism.
MoE allows us to build sparse models and decouple the model capacity (number of parameters) from the compute requirements, by only activating a subset of weights (experts) based on gating mechanisms. While MoE allows us to increase the model capacity without incurring the computation significantly, it still requires the same amount of memory bandwidth for large batch size. Memory bandwidth is currently the biggest bottleneck for training and inference of LLMs.
The Mixtral 8x7b design follows the Switch Transformer [https://arxiv.org/pdf/2101.03961.pdf]. It implements 8 experts in the FFN, and each token is routed to top-k (k = 2 in the Mixtral 8x7B) experts.
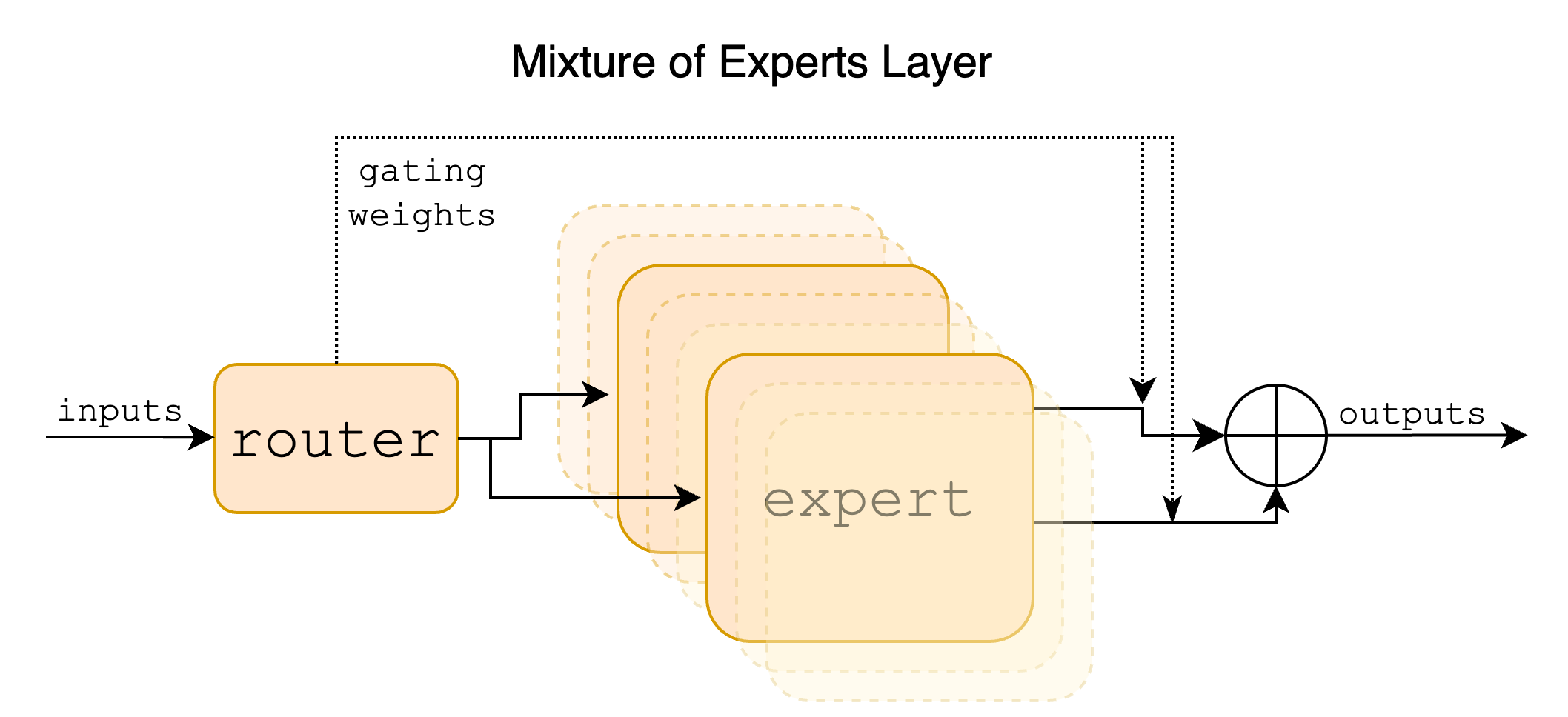
From https://github.com/mistralai/mistral-src/tree/main?tab=readme-ov-file#sparse-mixture-of-experts-smoe
3. Pretraining
Preliminaries
The objective of this project is to explore the limit of LLMs performance starting from known good baseline, with special focus on the role of data quality, objective diversity, factuality, and commonsense reasoning. The key insights / hypothesis for this work are two folds:
- The quality of the training data plays a critical role in model performance. While this has been known for decades, almost all LLM today (both open source and proprietary) focus on the size. Earlier research like “Textbooks Are All You Need" provided some insight and motivation for this work.
- Diversity of the objectives have shown to improve generalization. We think that increasing the diversity of the tasks with focus on quality, more than the size of training data would result in better generalization. Earlier research like “Robustly Optimized and Distilled Training for Natural Language Understanding” provided some insight and motivation for this work.
We start by resuming the pretraining process of the baseline model, which is Mixtral 8x7B with high quality data.
PreTraining data
Our pre-training data is a mixture of synthetically generated data specifically created to teach the model commonsense reasoning and general knowledge, including science, cause and effect, and daily activities, among others and a selected web data that is carefully processed to ensure high quality, factuality, and recency.
Web data
The web portion of our pre-training dataset are from the following websites:
- Wikipedia
- Wikiversity
- WikiBooks
- Wikivoyage
- Stack Exchange
Plus a selected number of web-pages referenced from mentioned websites. A special attention was paid to the quality of the data. The data was cleaned and prepared to ensure model inputs are high quality that includes:
- The boundaries between pages was respected so the model doesn't take input from two unrelated pages in one sample.
- Tables, info-boxes, Math LaTeX, and image captions was processed to be useful.
Syntactic data
The synthetic dataset was generated from several sources to improve the model understanding of commonsense, world knowledge, and factuality from the following sources:
- ATOMIC 2020 [paper] [website]
Common sense dataset contains about 1.07M of everyday inferential knowledge tuples about entities and events.
- ConceptNet [paper] [website]
Contains about 1.6M tuple of basic common sense knowledge about world entities.
- Quasimodo [paper] [website]
contains about 6.2M tuple of basic common sense knowledge about world entities.
We sampled a subset of the tuples, merged them by the subject, and filtered them using heuristics to ensure the educational value, then we converted the tuple into sentences. Examples of tuples that was removed and kept:
- Removed: PersonX borrows money oWant none
- Removed: PersonX borrows money xAttr needy
- Kept: PersonX borrows money xEffect becomes in debt
Training Details
The training data was roughly 10B tokens and we trained Mixtral 8x7B on 8 x H100 GPUs for several days. We call this model 'ROaE base v1 - Mixtral 8x7B' (Robustly Optimized and Enhanced). This model did not undergone alignment through reinforcement learning from human feedback (RLHF), nor has it been instruct fine-tuned.
4. Fine-tuning model : Factuality [v1]
Our objective with fine-tuning the model is to improve factuality, reduce hallucination, and show the generalization capabilities of our model. Our approach is largely inspired by "Fine-tuning Language Models for Factuality" [https://arxiv.org/pdf/2311.08401.pdf]. We're leveraging two key recent innovations:
- The ability to judge the factuality of open-ended text by measuring consistency with an external knowledge base.
- Direct Preference Optimization (DPO) algorithm which enables straightforward fine-tuning of language models on objectives other than supervised imitation, using a preference ranking over possible model responses.
For our fine-tuning we're using two datasets:
- Publicly available Instruction datasets from HuggingFace.
- Syntactic question answering data generated from Wikipedia websites. The questions generated programmatically and aims to cover realistic usage distribution, covers both short and long answers, and question types (e.g. where was personX born, write a bio about personX, summarize articleX, what is the timeline of entityX, Did entityX do eventY), We also randomly inserted adversarial fact in the prompt/question (e.g. perxonX is american, where was personX born, perxonY was born in germany, where was personX born).
We rank responses based on factuality, for questions where we expected a short answer (single fact) (e.g. where was personX born) we use the correct answer + heuristic to rank the responses, our heuristic rank concise answer higher. For open-ended questions (e.g. summarization, write bio) we using FactScore [https://arxiv.org/pdf/2305.14251.pdf] which leverage GPT-3.5 to extract the atomic claims from the model responses, then we used a small model (e.g. Mistral 7B) along with the source page to estimate the truthfulness [in follow up work, we plan drop the dependencies on external LLMs]. We call this model 'ROaE DPO v1- Mixtral 8x7B'.
5. Fine-tuning model : Multi-task learning [v2]
Given that we're trying to push the model performance to the limit and Peter Norvig famous quote “More data beats clever algorithms, but better data beats more data” and knowing that proprietary models like GPT-4, Claude, and others don't constrain themself with a specific publicly available datasets nor they publish the dataset used for their alignment process. We came up with alternative fine-tuning approach that leverage more objective diversity, and increase the training data size significantly.
Training data:
We first increase the size and diversity of the syntactic question answering dataset we created from Wikipedia, then we sampled a subset of the following publicly available dataset:
- CommonsenseQA [paper] [website]
A Question Answering Challenge Targeting Commonsense Knowledge with about 9K training examples.
- SocialIQA [paper] [website]
Commonsense Reasoning about Social Interactions with about 33K training example of multi-choice questions
- PhysicalIQA [paper] [website]
Dataset Reasoning about Physical Commonsense in Natural Language with about 20K training examples
- OpenbookQA [paper] [website]
Dataset for reasoning about commonsense and knowledge with about 5K training examples.
- ProtoQA [paper] [website]
A Question Answering Dataset for Prototypical Common-Sense Reasoning with about 8K training examples.
- ReCoRD [paper] [website]
Commonsense-based reading comprehension with a focus on news articles with about 100K training examples.
To ensure fairness and apple-to-apple we didn't not use any dataset that is currently widely used to evaluate the performance of LLMs (e.g. ARC, Natural QUestions, TriviaQA, MMLU, HellaSwag, WinoGrande, GSM8K).
Training Details
We trained a 5 models starting from the base model 'ROaE base - Mixtral 8x7B', each model trained using randomly sampled 90% of the entire fine-tuning dataset, also using different shuffling seed. We then merge the models using Fisher-Weighted Averaging [https://arxiv.org/abs/2111.09832]. Averaging the parameters of models that have the same architecture and initialization can provide a means of combining their respective capabilities. Fisher-Weight averaging have show to work slightly better any regular averaging [Model soup https://arxiv.org/pdf/2203.05482.pdf].
The merged model is our final model which we call 'ROaE DPO v2 - Mixtral 8x7B'.
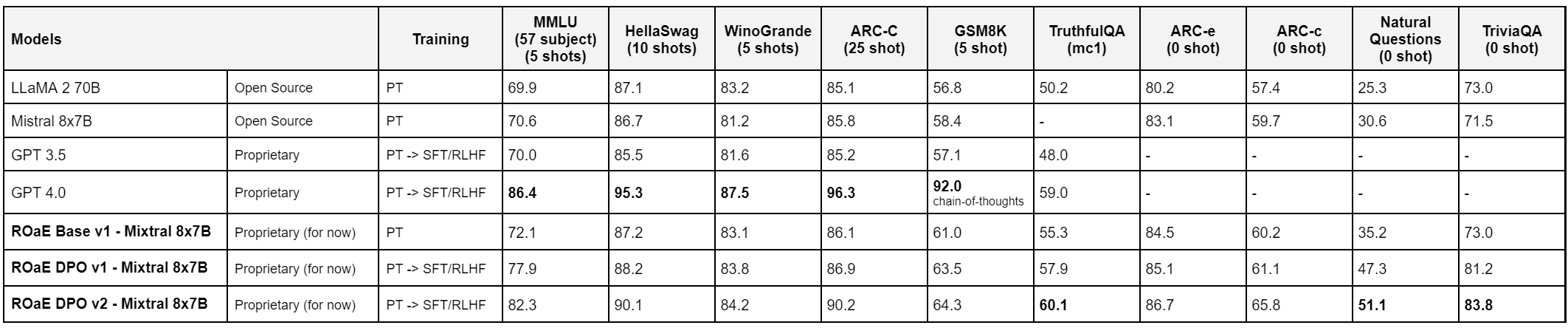
6. Results