TL;DR
- We present a new state-of-the-art base transformer model for machine reading comprehension that has almost 5% higher F1 score compared to ELECTRA-Base and 2% higher F1 score than the previous state-of-the-art base model (DeBERTa). This Model also outperforms BERT-Large.
- We present more experiments on our new multi-task pre-training method and knowledge distillation which led to this new model.
1. Introduction
In the previous installment of this series. I talked about Multi-task pre-training to improve generalization and set new state-of-the-art numbers in machine reading comprehension, NLI and QQP while also improving out-of-domain performance. In this installment, I’m going to talk about building the best base model. As a reminder, the ROaD-Large model is based on ELECTRA architecture but with extra multi-task pre-training phase and weighted knowledge distillation.
2. ROaD-Base v1.0 (baseline):
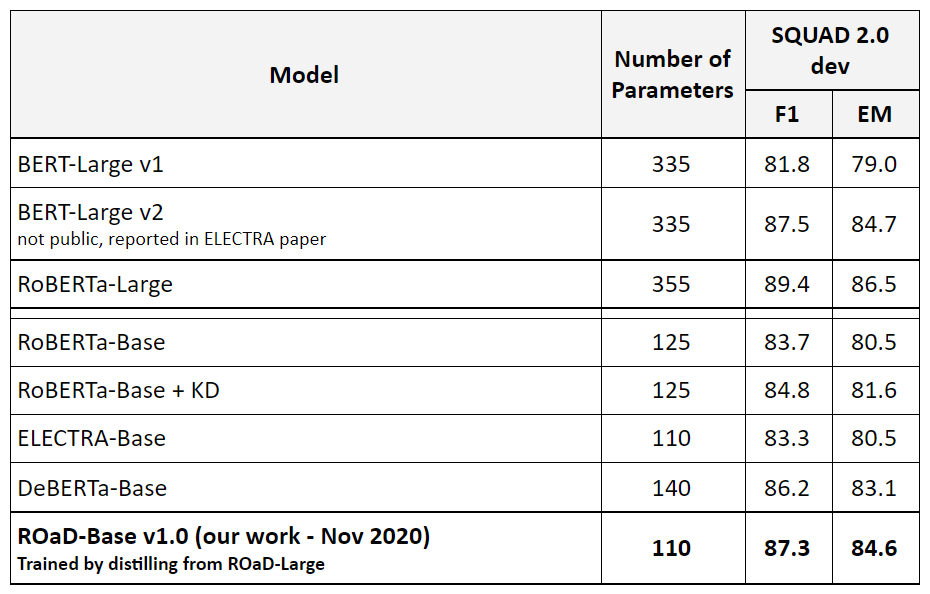
Our first version of ROaD-Base was built by simply distilling from ROaD-Large (which was trained using our multi-task pre-training and fine-tuned with weighted KD) which gave us the best base model by far (4% in absolute improvements over ELECTRA-Base, 1.5% higher than the previous state-of-the-art DeBERTa Base).
3. Entering ROaD-Base v1.1:
What is the best way to build base sized transformer models?! Traditionally, base models were built using the same techniques and procedures used to build the large models. But now with the proliferation of knowledge distillation we’re trying to change that. To answer this question, we did the following experiments:
- Is it better to just distill from a large model(s) or perform multi-task pre-training as we did in ROaD-Large?
- In distillation: What would be a good teacher, a regular ELECTRA-Large, ROaD-Large or a group of Base models?
- In distillation: What form of distilling works best, logits vs hidden-state vs a combination?
- In multi-task pretraining: Should we average the gradient across different tasks (one of the core ideas in ROaD-Large) and if so how many tasks?
4. Knowledge Distillation
4.1 Who would be a good teacher?
-
Student: ELECTRA-Base
-
Possible teachers: ELECTRA-Large, ROaD-Large, ELECTRA-Base, an ensemble of models
-
Experiment Setting: We used logits based knowledge distillation (Hinton et al., 2015) with a loss function that is defined as a weighted average of two objectives. The first objective is the original cross entropy (CE) with ground truth “hard targets”. The second objective is the Kullback–Leibler (KL) divergence with “soft targets” targets from the teacher’s predictions. We performed several runs for each setting to identify the best hyper-parameter (mainly lambda and temperature) and reported the best results.
Results:
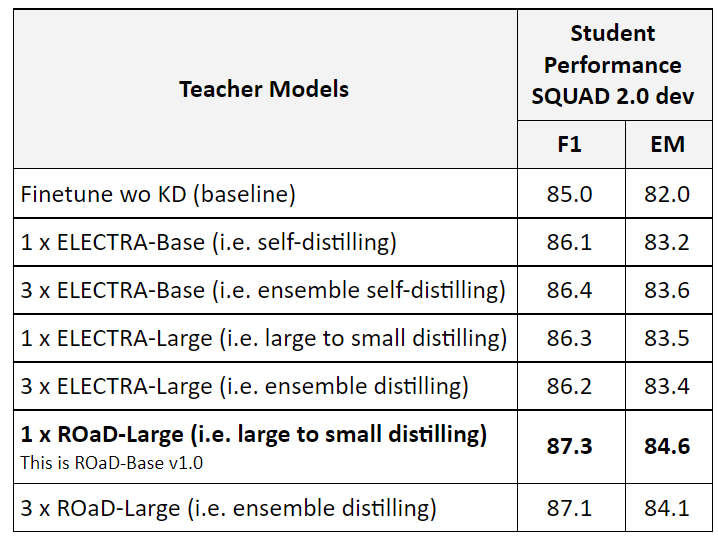
Observations and Take away:
- Distilling from a single larger model to smaller model seems to work better than self-distilling or ensemble self-distilling.
- Distilling from ROaD-Large is better than distilling from ELECTRA-Large which indicates that multitask pre-training makes the model a better teacher as well.
- Distilling from an ensemble of large models (ROaD-Large or ELECTRA-Large) is worse, my hypothesis is due to the increased gap in capacity between the teacher and student.
- ROaD-Large is the best teacher.
4.2 Is a distilled model a good teacher?
To answer this question we got the ROaD-Large (which was distilled from an ensemble of 3 ROaD-Large models) and ROaD-Large (without distillation) to see which one is a better teacher. Results:

Observations and Take away:
- Distilling from an undistilled model (a model that was not a student) is better than distilling from a distilled model (a model that was a student before).
Discussion:
There are many possible hypotheses for this, such as: Distillation make the model a bad teacher (similar to label smoothing - https://arxiv.org/pdf/1906.02629.pdf), the increased gap in the model capacity and accuracy (but I don’t buy this one, because in previous experiments with ROaD-Large iterative distilling in which student then become a teacher for the next model never worked). This definitely require more investigation.
4.3 What form of distillation works the best?
There are multiple forms of knowledge distillation, such as: using logits with KL loss, using the hidden state and/or attention of each layer with MSE loss (like TinyBert).
In the feature-based approach (hidden-state distillation) we project the hidden-state of the student model to match the size of the hidden-state of the teacher model. This projection is learned during the training. For the discrepancy in the number of layers we used the uniform mapping function as in the TinyBert paper (https://arxiv.org/abs/1909.10351), which means we map layer 24 -> 12, 22 -> 11 and so on. Based on experiments done as part of another project (Decoupling transformer - more in than in the near future) we decided to also try to distill the hidden-state of the last layer only (instead of every layer). Here are the results:
Results:
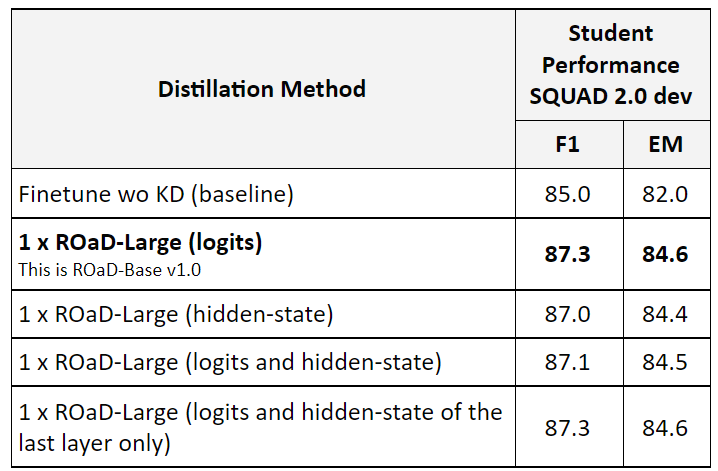
Observations and Take away:
- The addition of hidden-state matching losses is not sufficient on it’s own and doesn’t help that much.
Discussion:
While the TinyBert paper produced great results, their use-case is different from ours. TinyBert built a model from scratch (a model that wasn’t initialized using pre-training) so they used this form of knowledge distillation during the pre-training to try to make the new model match the representation of the teacher. In our case the model already has decent representation from the pre-training and changing it to match the teacher may not be necessary!
5. Multitask Pre-training
5.1. Can multitask pre-training help build a better model? Also how many tasks to average the gradient from?
Student: ELECTRA-Base
The typical approach of multitask learning is for each step we pick a task and perform forward, backward and update the model, and so on. In ROaD-Large work we discovered that while this approach worked for early models (e.g. BERT) it doesn’t improve upon the latest highly optimized model (e.g. ELECTRA). In ROaD-Large we averaged the gradient from 4 randomly selected tasks.
To answer if multitask pre-training help and how many tasks to average the gradient over, we come up with the following experiment: perform multitask pre-training with 1, 2, 4 and 8 passes (in each pass we pick a random task and compute the gradient) while trying to keep the batch size constant at 512. We performed 40,000 steps. For the finetuning we used logits knowledge distillation from ROaD-Large as well.
Results:
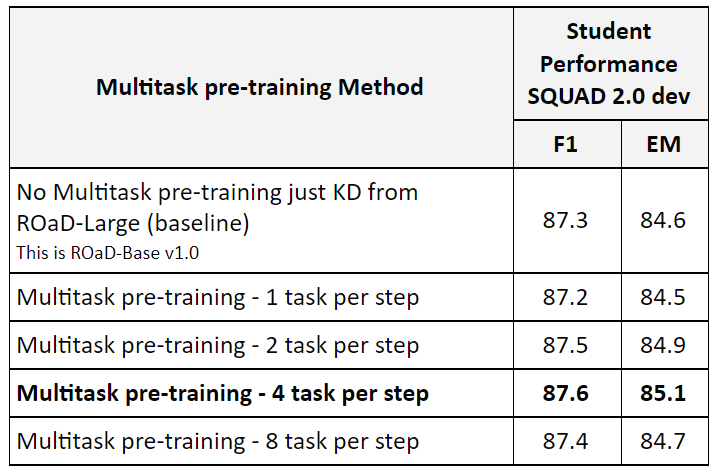
Observations and Take away:
- Multitask pre-training without gradient averaging does hinder the performance slightly compared to no multi-task pretraining.
- Multitask pre-training with gradient averaging, especially from 4 or 2 tasks, does improve performance.
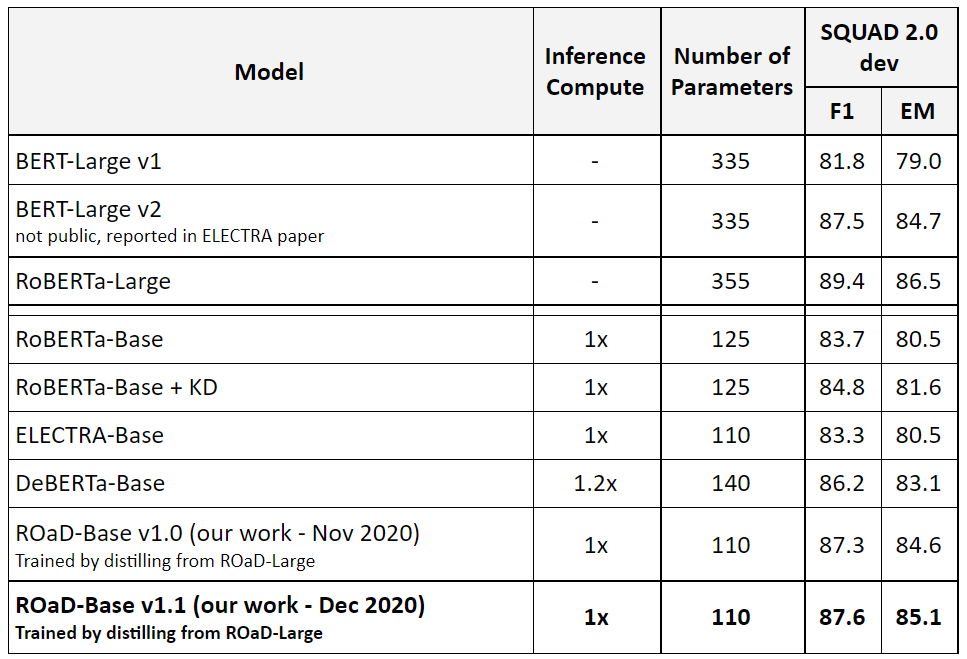
6. Final Model
Putting everything together. We started from ELECTRA-Base (our baseline) we performed multitask pre-training for 40K steps while averaging the gradient from 4 tasks, then finetune with logits knowledge distillation from ROaD-Large (a model that was not a student).
The results, ROaD-Base v1.1 the best base sized Transformer model with about 5% higher F1 score in SQUAD 2.0 dev than the baseline. About 2% higher F1 and EM score in SQUAD 2.0 dev compared to the previous state-of-the-art DeBERTa. The model also outperforms BERT-Large.
Results:
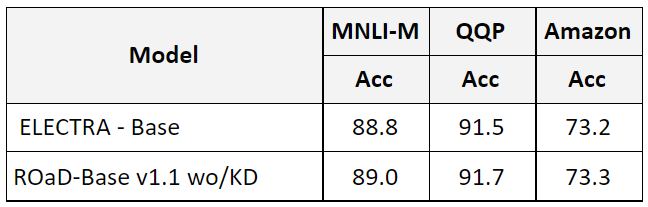
Outside of MRC the new model performs well. Here are the results on MNLI, QQP and Amazon. No knowledge distillation was performed, just a single fine-tuning experiment with the recommended hyper-parameter from ELECTRA paper.