
Build state-of-the-art Transformer models for QnA, NLI and NLU.
TL;DR
- We present a new multi-task pre training method that improves the transformer performance, generalization, and robustness.
- We present a new variation of knowledge distillation that improves the teacher signal.
- A new state-of-the-art results in SQUAD 2.0 MNLI, and QQP. These improvements come without any increase in inference compute. This model has less weight than ELECTRA.
1. Introduction
The goal of this project was to push the state-of-the-art performance of transformer models (focusing on Question Answering and NLI). while simultaneously trying to address some of the transformer models issues such as: Robustness (small paraphrasing leads to loss of accuracy) and Generalization (model trained on one dataset, performs poorly on another dataset of the same task), Answerability (models tend to answer even if there is no answer in the context). The goal is to do this without incurring any increase in inference computation.
This work does not target new pre-training objectives or methods, such as RoBERTa and ELECTRA; instead it builds on top of ELECTRA and explores other multi-task pretraining and knowledge distillation.
2. Baseline
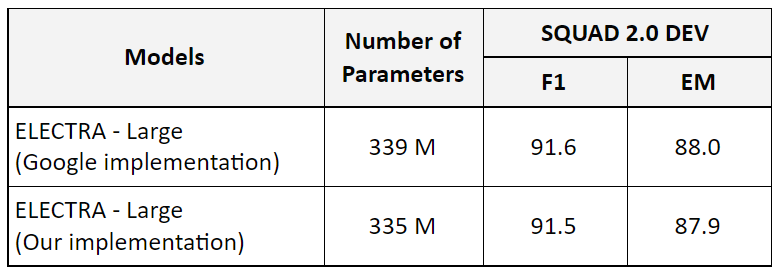
We selected ELECTRA (Clark et al., 2019) as our starting (‘baseline’) model since it represents the current state-of-the-art. That being said, our implementation differs in one aspect, ELECTRA question-answering module predicts the answer start and end positions jointly and has an ‘answerability’ classifier. We use a simplified question-answering module which independently predicts the answer start and end positions. We train the model to predict position ‘0’ (the CLS token) if the question is not answerable, which is similar to the original BERT model. Our experiment shows that this simplification impact on performance is marginal to non-existence, yet it reduces the number of parameters by more than 4 million.
3. Multi-task pretraining
Transformer models are trained in a self-supervised manner to predict a masked in a context, predict the next sentence or to distinguish “real” input tokens vs “fake” input tokens generated by another neural network in the case of ELECTRA.
Those objectives allow the models to learn about language structure and semantic, but its lack aspects of human language learning such as: humans learn to use language by listening and performing multiple tasks (e.g. expressing emotion, making statements, asking and answering, etc.) and they apply the knowledge learned from task to another to help learn new task. Also, language doesn’t exist on it’s own, language exists in a physical world that contains physical objects, interactions, general and common-sense knowledge, and a variety of sensory input e.g. vision, voice, etc. - but this topic for another day.
Multi-task pretraining is not a new idea, it has been proposed a few times (Caruana, 1997; Zhang and Yang, 2017; Liu et al, 2019). The goal of our MT-Pretraining is to teach the model a diverse set of realistic tasks to help it better understand language and generalize better.
3.1 Our Approach
Our model architecture is identical to ELECTRA. The encoding layers are shared across all tasks. Each task (a task could span multiple datasets) has its own output heads.
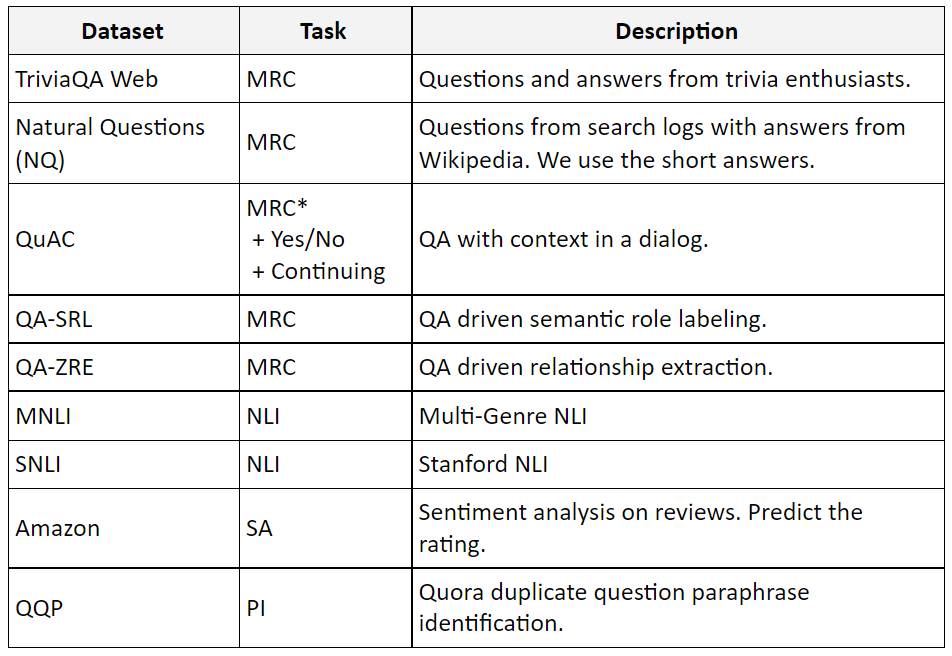
3.2 Tasks
We selected 9 diverse publicly available datasets and categorized them into 6 tasks (model heads).
3.3 Training Procedure
To train out MT-Pretraining model, we start from a pre-trained ELECTRA-Large, we perform the multi-task pretraining then fine tune the model for a specific task.
In the multitask pre-training stage, we use Adam optimizer to update the parameters of our model (i.e. parameters of all shared layers and task-specific layers). In every training step, we perform multiple passes (forward, compute loss and gradian accumulate) using randomly selected dataset. Which means, we average the gradient across tasks.

3.4 Similarity to MT-DNN
MT-DNN combines BERT with second MTL pretraining on supervised tasks to achieve improved performance on several NLU tasks. ROaD approach to MTL pretraining is similar to MT-DNN but it differs in two major ways: (1) We average the gradient across several tasks (randomly selected tasks). MT-DNN performs a step based on the gradient of a single task. (2) We use the same prediction head for each task across datasets, whereas MT-DNN uses a separate head per dataset. For example, MRC tasks such as TriviaQA, NQ and QuAC share the same prediction head.
We experimented with the MT-DNN approach and we could not improve upon ELECTRA-Large, but we can re-produce their improvements on the original BERT.
3.5 Experiment and Results
We compare ROaD MTL pretraining with MT-DNN (using our selection of datasets). We trained the model for 20,000 steps with a batch size of 512. We used a learning rate of 3e-4, layer-wise learning rate multiplayer of 0.75, 500 warm-up steps and linearly decreased the linear rate afterward. After the multi-task pretraining we fine-tuned the model on the target dataset.
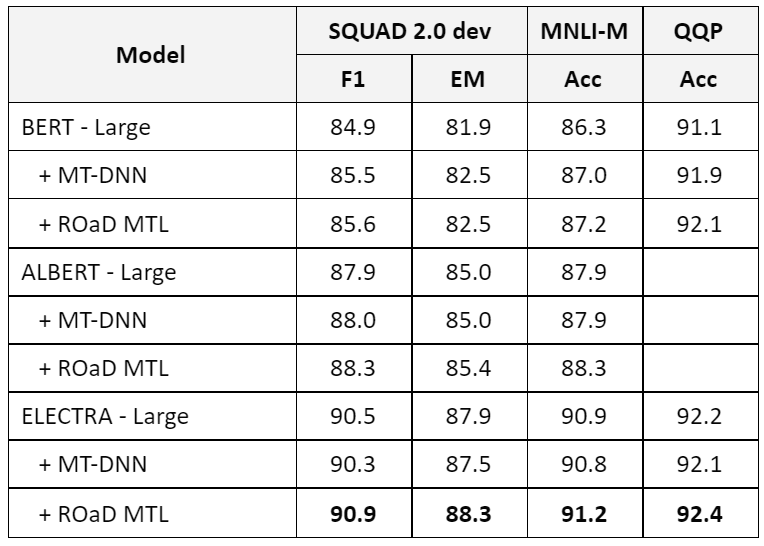
ROaD MTL consistently outperforms the baseline model and MT-DNN in all tasks and models. While we were able to reproduce MT-DNN improvements on the original BERT. MT-DNN didn’t improve upon ALBERT and degraded the ELECTRA performance. Our hypocrisies are the following:
The original BERT that MT-DNN used, was trained for significantly a smaller number of steps, on smaller training data using only 6% of the FLOPs used to train ELECTRA-Large and RoBERTa-LARGE.
Improving upon extremely optimized and tuned models (e.g. ELECTRA-Large) that already found a good local-minima is very difficult, therefore we hypothesis that moving such model in the direction of a single task is insufficient to improve model overall performance, therefore averaging the gradient from different tasks prevent the model from wondering in the wrong direction (a direction that is beneficial for a single task).
Generalization
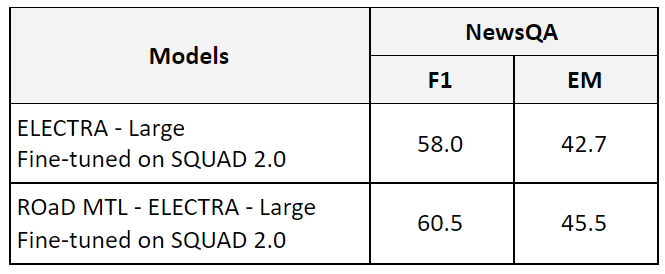
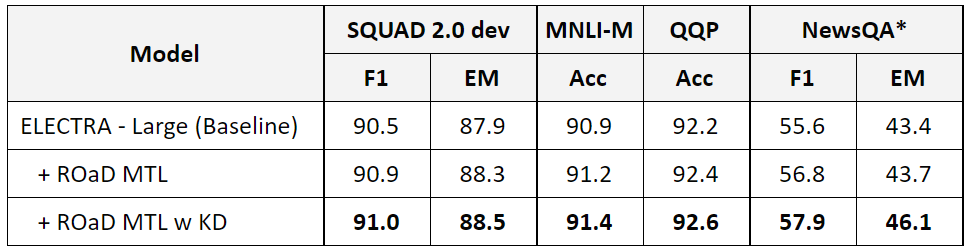
Improving generalization and robustness are an important theses of multi-task pretraining. To test that evaluate models on NewsQA. using a model that was fine-tuned on SQUAD 2.0 dataset. Which is OOD question-answering dataset that the model never seen or trained on. Here are the results:
Knowledge Distillation in Multi-task Pretraining
We also investigated the benefits of KD during Multi-task pretraining. We use logit (Hinton et al., 2015) KD. The procedure works like this: Fist, finetune teachers on each training dataset. Then, use the teacher to generate soft targets for each dataset. Finally, we use the generated soft targets with existing hard targets to pretrain a ROaD MTL model. During the MTL pre-training we define a loss function that is a weighted average of two objectives. The first objective is the original cross entropy (CE) with ground truth “hard targets”. The second objective is the Kullback–Leibler (KL) divergence with “soft targets” targets from the teacher’s predictions. For the second KL objective, we use softmax with high temperature T > 3 to generate a softer probability distribution over classes. We set the same temperature in the teacher and student model.
Using KD during the MTL pre-training step with regular finetuning improves the model performance even further since it provides a richer pre-training singal. In particular, on the out-of-domain and out-of-distribution NewsQA dataset (model used on this dataset was fine-tuned on SQUAD 2.0). Which demonstrates that models trained with KD during MTL pretraining were able to learn better universal language representation. In addition, the MNLI-M 91.4% and QQP 92.6% results are new best published accuracies for a single model.
4. Knowledge Distillation
Knowledge Distillation is the process of transferring knowledge from a model to another model, usually a smaller one.
Supervised Machine learning relies on labels. Yet these labels provide limited signals. For example, in image recognition tasks, the labels are one-hot vectors with the entire probability assigned to the correct label; those labels do not provide any signal about the incorrect labels. For example, An image of a cow is relatively similar to an image of a bull, but many times less similar to an image of a chair. This similar structure is very valuable and could be acquired from a teacher model.
The training objective is to maximize the average log probability of the correct answer, but a side-effect of the learning process is that the model assigns probabilities to all classes (correct and incorrect). The relative probabilities of incorrect answers provide a similarity structure that could be used to improve the training signal of a student model.
For this work, we’re using Hinton et al., 2015 knowledge distillation formulation, which works at the logits level. We’re distilling from an ensemble of three same size MT-Pretrain or ELECTRA models.
While KD provides an increase in performance. One of the known limitations of knowledge distillation is that students are limited by the teacher’s performance.
We experimented with an approach called Teacher Annealing, in which the student early on tries to imitate the teacher then toward the end the student mostly relies on the gold-standard labels so it can learn to surpass its teachers. While this approach seems to be very promising and worth investigating further, we weren’t able to improve upon the typical KD after several experiments.
We also experimented with iterative KD aka born-again-networks (Furlanello et al., 2018) but we weren’t able to surpass the typical KD.
4.1 KD with improved signal
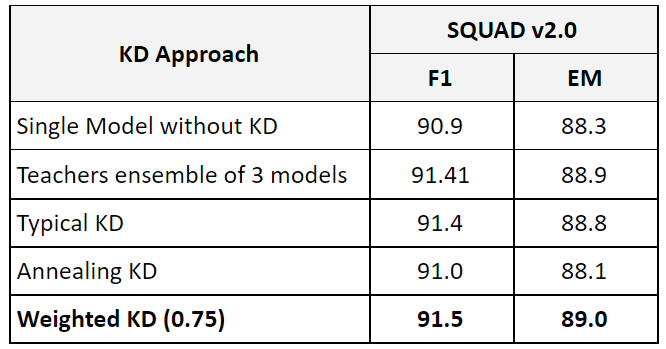
After those experiments, we turned our attention to the core question, how to improve the teacher signal. After several experiments we arrived at Weighted KD, which scales the logits according to the signal quality (correctness). Here is how to procedure work:
Given M models, Input (example input features, target (ground truth targets), and W scaling factor (hyperparameter W < 1, typically 0.75). We scale the logits of the incorrect teacher by W and distribute the remaining weight to the correct teachers. The final weighting is computed such that to preserve the logits average value range. This way the student can focus on the information from the correct teachers. Here is the procedure:

4.2 Experiment and Results
We compared the different knowledge distillation approaches. Here are the results:
5. The Final Model
The final model is called Robustly Optimized and Distilled ELECTRA (ROaD-ELECTRA). Is trained using the presented Multi task pre-training, finetune on SQUAD (no data augmentation) with weighted knowledge distillation from ensemble of three same size models. Here are the results on SQUAD 2.0 dev and out of domain dataset NewsQA (a dataset the model has never seen):
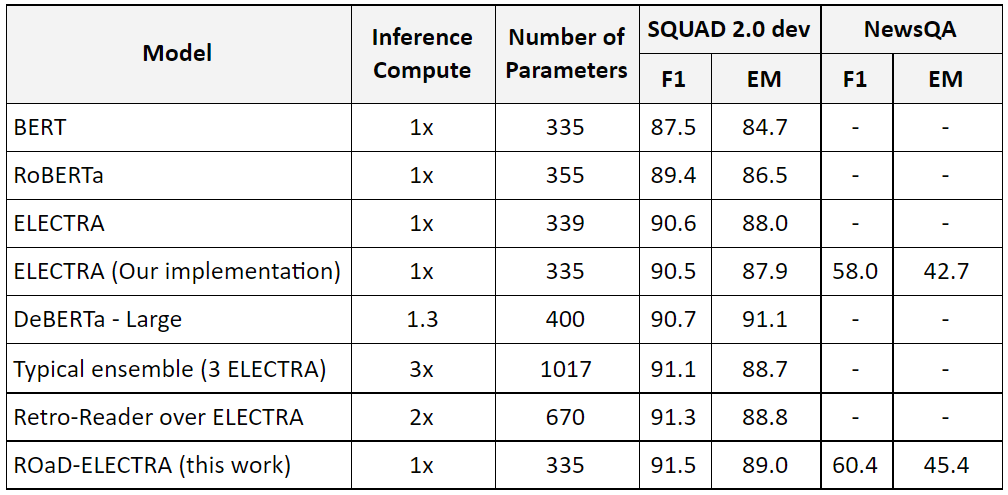
91.6% F1 and 89.0 EM represent the highest score for a single model on SQUAD dev.
This model also generalizes better on out of domain datasets.
This model also outperforms some ensembled models as well.