
It seems tricks (e.g. Data Augmentation, Label smoothing, Mixout) are approaching their limits to improve SoTA models on SQUAD 2.0 and NQA Natural Language Understanding models have been getting better and better, from ELMo, BERT, GPT, to ALBERT, RoBERTa, ELECTRA and DeBERTa. We already suppress human performance in many narrow tasks. The main way those models have been improving are:
- More training data
- More training steps
- Better objective
Recently I was reciting a slew of old tricks to see if we can improve the latest NLU model even further and I discovered this: The better or well tuned the model is, the less effective the tricks are. Take a look at this set of experiments:
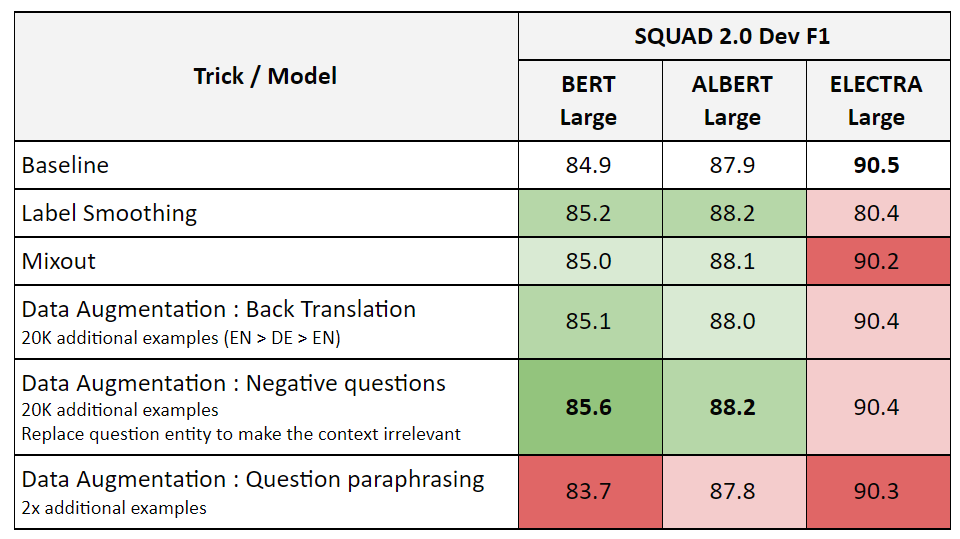
Those results suggest either:
- SQUAD 2.0 is no longer an effective way to measure QA capabilities.
- Current BERT encoder-only architectures are highly optimized and approaching the limits of potential improvements and maybe it’s time to look at ways to improve the architecture similar to what (e.g. DeBERTa, Switch-Transformer) did.